

Performance and Efficiency at Every Scale
Building on Intel's extensive experience in accelerator design and deep expertise in microarchitecture and software, Intel extends its AI acceleration capabilities across a broader range of applications with two flexible deployment options based on form factors: an 8-GPU UBB or a traditional dual-slot PCIe card. Designed for scalability and versatility, the Intel Gaudi 3 platform uses an open software ecosystem, optimized to meet diverse performance, power, and budget requirements. from large-scale AI factories to highly regulated industries.
Scaling AI with the Intel Gaudi 3 AI Accelerator in GIGABYTE Servers
Engineered for large-scale AI models across hyperscalers, clusters, and enterprises, the combination of Intel Gaudi 3 AI accelerator OAM card (HL-325L) and universal baseboard (HLB-325) delivers exceptional performance for large-scale AI training and inference. With advanced compute technologies and networking, it meets the needs of AI research, hyperscale computing, and cloud environments. GIGABYTE has custom built an 8U air-cooled server, G893-SG1-AAX1, featuring an optimized thermal design, providing the robust infrastructure required for high-performance AI acceleration within a standard air-cooled server.

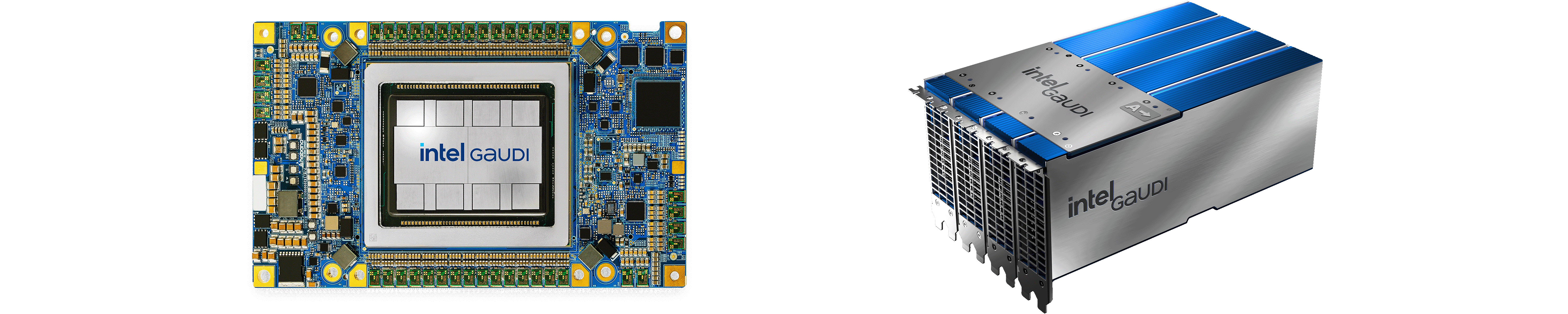
Intel Gaudi 3 UBB ( 8 x OAM cards)

G893-SG1-AAX1
Designed for enterprise AI applications, the Gaudi 3 PCIe card (HL-338) is ideal for AI inference, secure on-prem workloads, and cost-efficient AI deployments. With improved power efficiency and a compact PCIe form factor, it enables organizations to scale AI efficiently. GIGABYTE provides compatible 2U and 4U servers that integrate seamlessly into existing infrastructures, optimizing rack space and reducing operational overhead.

Intel Gaudi 3 PCIe

G494-SB0-AAP2
GIGABYTE is ready to deliver end-to-end solutions for the Intel Gaudi 3 AI Accelerator. From design to deployment, our optimized server platforms ensure seamless scalability and rapid time-to-value, so you can deploy AI infrastructure whenever your business is ready to move forward.
Designed for the Real-World Demands of AI

Scalable Performance for Every AI Need
Delivers powerful compute performance and memory bandwidth for workloads from enterprise inference to massive LLMs, and adaptable across scales and industries.

Flexible Deployment for Any Infrastructure
A unified architecture with OAM UBB and PCIe options that integrate seamlessly into diverse data centers, optimizing for space, power, and performance.

Optimized Power and Thermal Efficiency
Engineered to balance high throughput and low energy use, enabling reliable, high-performance AI acceleration in standard air-cooled systems.

Open and Ready Software Ecosystem
Supports leading AI frameworks and precision formats including FP8 and BF16 with day-zero access to top LLMs, accelerating deployment and developer productivity.
Intel Gaudi 3 AI Accelerator Specifications
| Product | HL-325L OAM Mezzanine Card | HL-338 PCIe Add-In Card |
| Architecture | 5th Generation Tensor Processor Core | |
| Supported Datatypes | FP32, BF16, FP16 & FP8 (E4M3 / E5M2) | |
| MME Units | 8 | |
| TPC Units | 64 | |
| HBM Capacity | 128 GB | |
| HBM Bandwidth | 3.7 TB/s | |
| On-die SRAM Capacity | 96 MB | |
| On-die SRAM Bandwidth (read/write) | 12.8 / 6.4 TB/s | |
| Networking (bidirectional) | 1200 GB/s | |
| Host Interface | PCIe Gen5 x16 | |
| Host Interface Peak Bandwidth | 128 GB/s (64 GB/s per direction) | |
| Media Decoders | 14 | |
| TDP | 900W | 600W |
| Form Factor | OCP OAM 2.0 Mezzanine card | FHFL Dual-slot PCIe Gen5 x16 card |
| System Configuration | 8-card connected with HLB-325 universal baseboard | 1 group of 4-card via top board (HLTB-304) or 2 groups of 4-card via top boards (2 × HLTB-304) |
| Networking (Scale-up/Card-to-Card) | 21 × 200GbE through HLB-325 universal baseboard | 18 × 200GbE through HLTB-304 Top Board |
| Networking (Scale-out) | 3 × 200GbE through HLB-325 universal baseboard | Through Host-NIC |
*The HLTB-304 board allows connectivity of 4 × HL-338 cards through 6 × 200GbE links from each card to the other cards, 18 links of 200GbE total per card.
Applications

HPC
Complex problem-solving in HPC applications use numerical methods, simulations, and computations to achieve significant insights. While traditionally less dependent on GPUs, the overwhelming parallel computing power of GPGPUs has greatly accelerated the development of HPC in recent years, making hybrid configurations a growing trend in modern supercomputers.

AI
With the rapid adoption of AI, from general applications to the fast-evolving deep learning, GPGPUs have become a game changer for the industry. The parallel processing capabilities of GPGPUs allow for the handling of massive datasets and complex algorithms, which are essential for training and deploying AI models. As a result, AI has become the key to making modern systems faster and “smarter” in the most efficient way.

Data Analytics
In data-intensive applications such as big data and computational simulations, systems rely heaving on GPGPUs for high parallel processing, low latency, and high bandwidth to facilitate data mining and large-scale data processing. The ability of GPGPUs to handle vast amounts of data simultaneously not only accelerates the processing of massive datasets but also enables more accurate and timely insights, driving informed decision-making in fields like finance, healthcare, and scientific research.



Resources


GIGAPOD: The Future of AI Computing in Data Centers
Watch Video






Topic